For context: Recon by AaronGoldman · Pull Request #124 · ceramicnetwork/CIPs · GitHub
So I was asking if using bloom filter would speed up the recon proces as it was used in some prior works mentioned in the paper
https://www.youtube.com/watch?v=xuddEiu-t-8&ab_channel=HeidiHoward
you: [ your initial keys ]
they: [ their initial keys ]
-> ( request ) [ their keys after processing request]
<- ( response ) [ your keys after processing response]
Current
you: [ape,eel,fox,gnu]
they: [bee,cat,doe,eel,fox,hog]
-> (ape, h(eel,fox), gnu) [ape,bee,cat,doe,eel,fox,gnu,hog]
<- (ape, h(bee,cat), doe, h(eel,fox), gnu, 0, hog) [ape,doe,eel,fox,gnu,hog]
-> (ape, 0, doe, h(eel,fox,gnu), hog) [ape,bee,cat,doe,eel,fox,gnu,hog]
<- (ape, 0, bee, 0, cat, h(doe,eel,fox,gnu), hog) [ape,bee,cat,doe,eel,fox,gnu,hog]
-> (ape, h(bee,cat,doe,eel,fox,gnu), hog) [ape,bee,cat,doe,eel,fox,gnu,hog]
<- (ape, h(bee,cat,doe,eel,fox,gnu), hog) [ape,bee,cat,doe,eel,fox,gnu,hog]
After using a bloom filter
you: [ape,eel,fox,gnu]
they: [bee,cat,doe,eel,fox,hog]
-> ([ape, h(eel,fox), gnu] + bloom(eel,fox)) [ape,bee,cat,doe,eel,fox,gnu,hog]
<- ([bee,cat,doe,hog] + [ape, h(bee,cat), doe, h(eel,fox), gnu, 0, hog] + bloom(ape..hog)) [ape,bee,cat,doe,eel,fox,gnu,hog]
And @AaronDGoldman pointed out that bloom filter does have its bandwidth cost with it
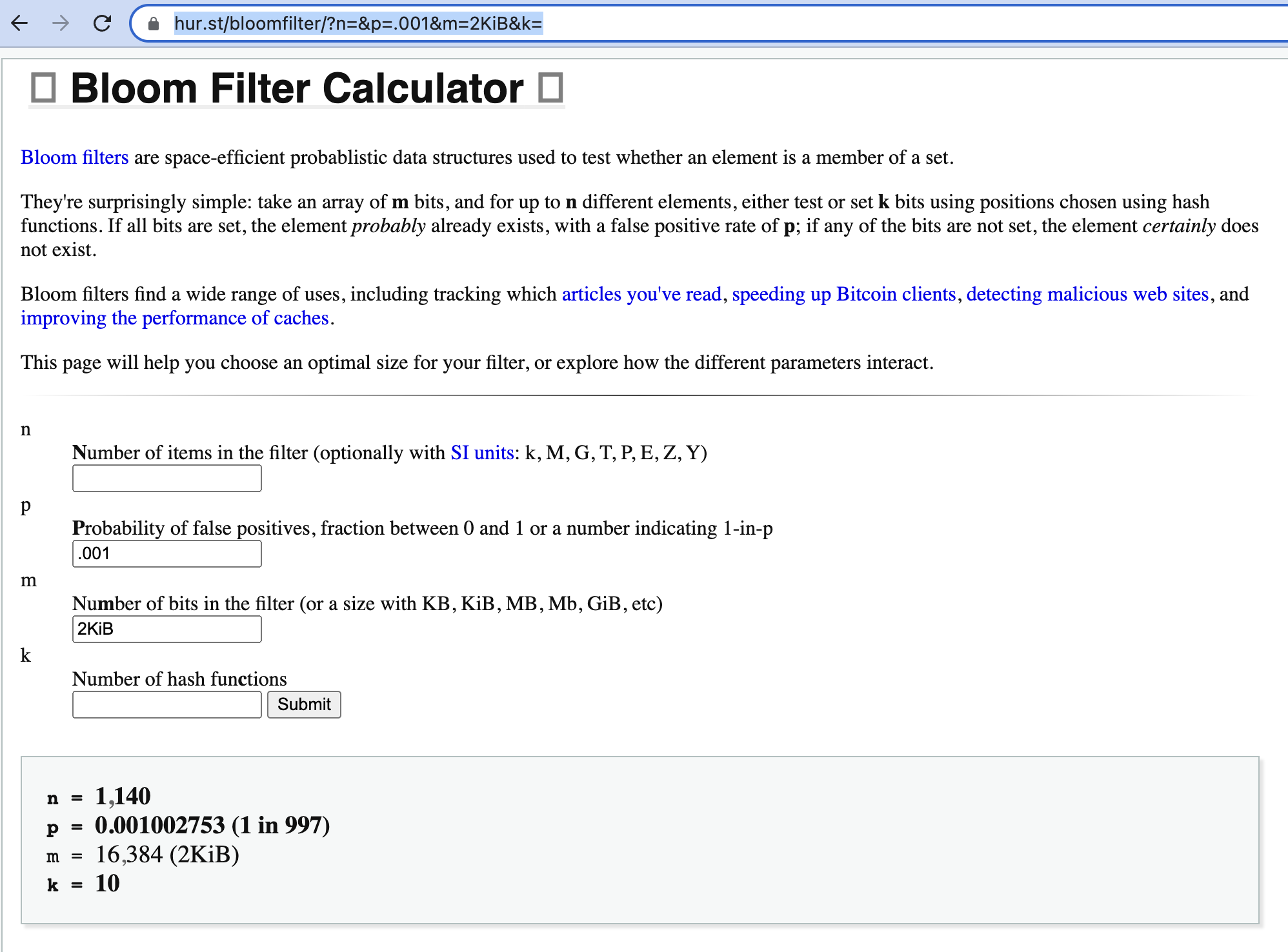
Bloom filter calculator
e.g. If we through in a 2KiB filter we could probably send all remaining key when we got to about 1,000 keys in a range. Speeding up the last few rounds.
Markdowns rendering in the last few section of the doc seems broken
https://cips.ceramic.network/CIPs/cip-124