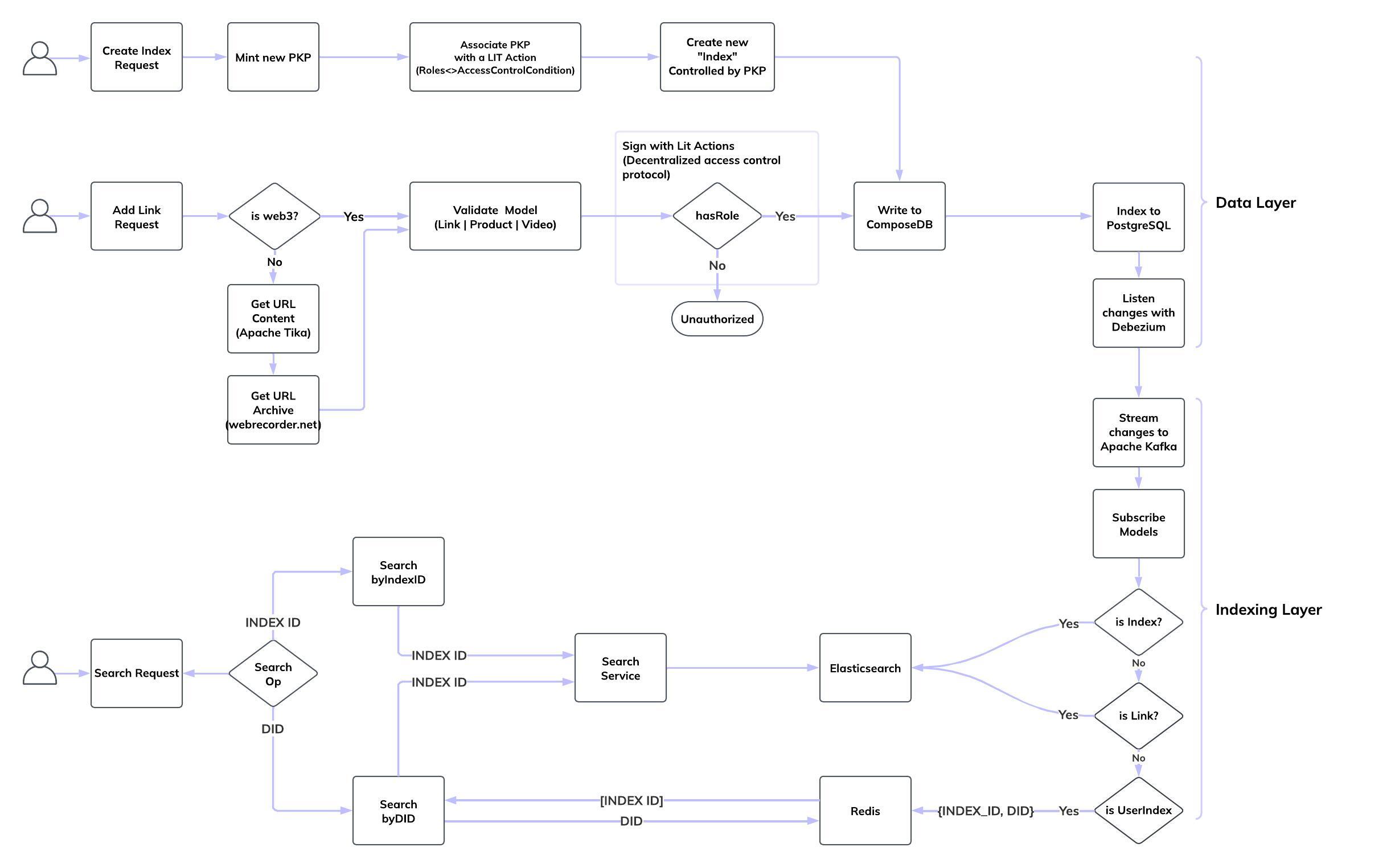
We are currently indexing ComposeDB into Elasticsearch using the following pipeline: ComposeDB → PostgreSQL → KafkaConnect → Apache Kafka → Consumer → Elasticsearch.
Ideally, we would like to remove PostgreSQL and KafkaConnect from the pipeline and instead stream updates directly to Kafka. What are your thoughts or plans regarding the use of the native Apache Kafka indexer? As a fan of Kafka and Ceramic, I’m very excited about this possibility.
Also, here is the architecture of index.as. Any feedback would be greatly appreciated.
Hey @seref thanks for sharing this! It’s a very interesting implementation. At the moment we don’t have plans for directly supporting Kafka for indexing. It is something we are discussing and looking into potential solutions, but it’s very early and we cannot guarantee that it will result into actual implementation. We will definitely keep the community up-to-date if we end up having more concrete plans for it.
This is currently the best approach for information exposed by ceramic. We are looking at exposing a more streaming friendly API, which would notify of metadata (e.g. new models and documents), and events on documents. Would this be something that would solve your use case better?