Thanks to @mohsin, @cole, and @nathanielc for discussion and insight around this topic.
This post describes an approach for protocol minimization that enables engineering efforts to move faster on the things that really matter (i.e. decentralization of CAS and node incentivization). Currently the Ceramic protocol is tightly coupled with ComposeDB inside of the js-ceramic code base. There’s an ongoing effort to migrate parts of the js-ceramic codebase into rust-ceramic. The primary driver of this to enable a purpose built data synchronization protocol Recon. Beyond that there’s an open question of what parts of the protocol belongs in rust and what in the js codebase. Really this is a question about the protocol boundary between Ceramic and ComposeDB, since we want the Ceramic protocol to be fully implemented in Rust.
Move fast on what matters
Beyond Recon there are two main things that are urgently needed by the protocol. Providing a decentralized alternative to CAS and an incentive mechanism for running nodes. Both of these are big problems that we need to invest a considerable amount of engineering effort into. Considering this it seems like it would be prudent be extremely conservative with what protocol features we port over from js-ceramic to rust-ceramic, and consider rewrites only of logic that is strictly necessary. Since the more time we spend on rewriting, the less time we have to build what actually matters.
What can rust-ceramic not go without?
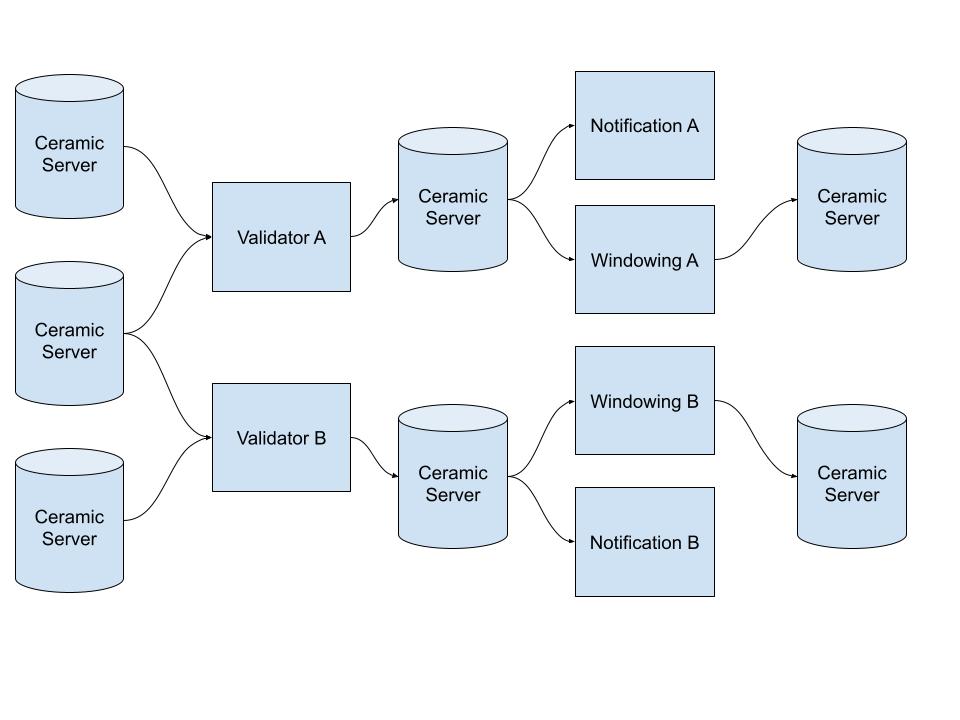
Which parts of js-ceramic is actually critical to rewrite in our rust code base then? Well in it’s current iteration Recon blindly accepts events from other nodes. This opens up an attack vector where malicious peers can DoS the network by spamming fake events. The rust code base thus needs to be able to validate events before propagating them further in the network. Besides this, not much else is required.
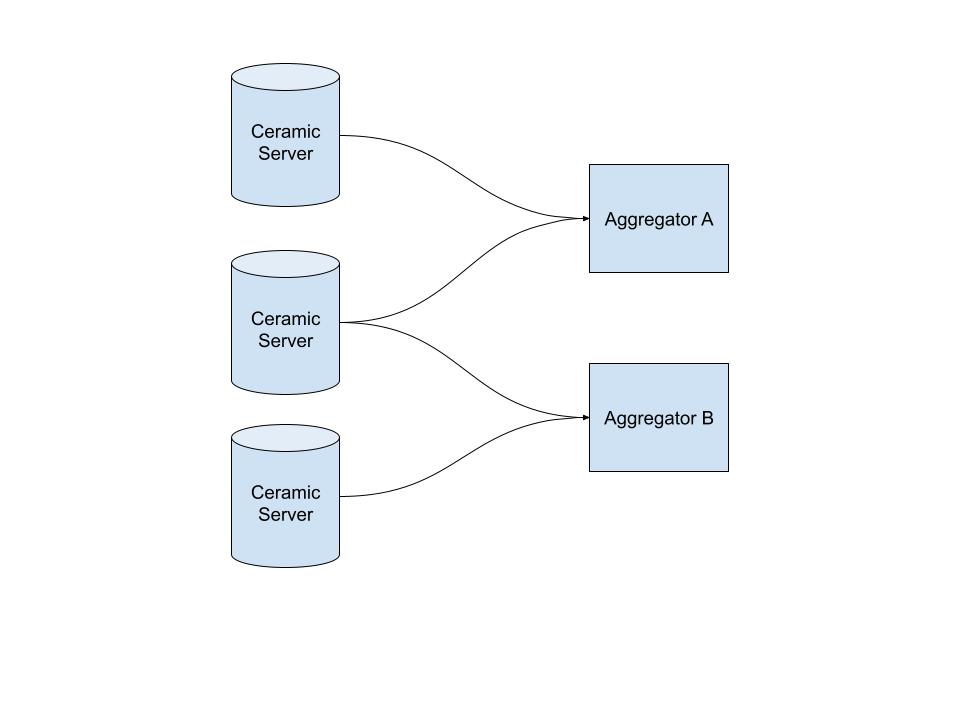
None of these features takes us closer to CAS decentralization or node incentivization:
- “Firehose” API
- Aggregation of events into JSON documents
- Conflict resolution
- Requesting anchors from CAS
These features can happily live on inside of the javascript code base.
Minimal event validation
So if Recon doesn’t require full stream conflict resolution, how would the rust code base actually validate events?
- InitEvent - validate signature against controller
- DataEvent - get InitEvent from
idfield, validate signature against controller - TimeEvents - validate time information
Ideally Events signed using an OCAP with an expiry date would only be considered valid if a TimeEvent exists that confirms the signature was produced within the validity window.
Note that the above description doesn’t actually require validating any prev field. This means that for a consumer of an the event API exposed by rust-ceramic, multiple branches of stream history would be visible. This is actually a good thing since it enables late publishing traceability. Note also that this approach does not require cip145 to be implemented.
A first step towards decentralizing anchoring
One first step that can be taken towards decentralized anchoring is to enable rust-ceramic nodes to self anchor. This would enable large node operators to remove the reliance on a trusted service in CAS. It could also potentially make anchoring more performant and robust because it removes a lot of redundant work being done today (e.g. network traffic, event validation).
Key to note here is that now the prev field becomes relevant in the rust code base. The node could continually be building a tree as new events come in. If a new event points to an event already in the tree using the prev pointer, the past event can be replaced. Thus reducing the number of events anchored in the batch (since the events from prev are implicitly anchored).
Javascript cleanup
Now the above changes leaves us with much of the js-ceramic code base intact. The main optimization we could easily implement would be to remove signature validation, while keeping the conflict resolution logic as is. Here’s a few other things to consider:
- Merge our main two javascript code bases js-ceramic and js-composedb into a monorepo, or make js-ceramic into more of a middle ware that js-composedb imports
- Requesting anchors from CAS remains in the javascript code base until fully replaced by decentralized alternative(s) in Rust
- Consider if the “Firehose” API should be considered a part of ComposeDB