Hello everyone!
With ComposeDB on Ceramic mainnet now for four months, we have been successfully solving decentralized, verifiable, and composable data for dApps. Continuing our focus on supporting reputation use cases, we are exploring how to solve the needs of DAO communities and the coordination tools they use.
We have heard interesting feedback already about the overlap between reputation and DAOs - governance delegates are critical participants in the ecosystem.
In response to feedback asking us to demonstrate how ComposeDB might be used, we decided to outline an initial proposal on how we understand data needs in this context, along with a concept of how a solution on ComposeDB might be architected and implemented.
Request for Feedback Outline and Intention
The purpose of this post is to outline an initial standpoint on how these three layers could potentially be implemented in concrete terms by proposing:
- A collection (composite) of data models corresponding to the identity signals outlined above
- A pre-packaged, simple way to deploy the models
- Context around our decision-making related to the two bullet points above
Data Categories Overview
DAO data in particular presents an exciting use case well suited for ComposeDB on Ceramic and we’re delighted to hear your thoughts on the usefulness of these concepts. We think about data ownership for this use case as breaking down broadly across four categories:
- Self-defined DAO-agnostic identity
This identity category is agnostic of any specific DAO and controlled by the individual. These primitives are designed to span multiple use cases.
- Delegate/Member/Contributor self-defined DAO-specific identity
This category is DAO-contextual and is also controlled by the member/delegate/contributor.
- Group-defined identity and attestations
Identity signals that fall into this bucket can both reference group-defined identity (such as descriptive metadata about the organization), as well as attestations related to individuals, and are controlled by the DAOs themselves.
- Third-party reputation signals
This reputation category points to specific individuals, thus acting as trust signals, and represent the outcome of an underlying attribution framework. This grouping would be controlled and authored by third-party organizations.
ComposeDB Reference Documentation
For those new to ComposeDB and how creating data models work, here are several reference points you will find helpful as you read this post:
Defining Data Relations in ComposeDB
Note: the schema definitions you’ll see in the following code blocks were slightly reformatted for the purposes of this post. Please reference the exact schema definitions in the GitHub repository within the “Getting Started” section toward the end.
Finally, as you read through this post and think about data interoperability between models, consider benefits such as those outlined below, and how these benefits extend to both data producers and data consumers:

Self-Defined, DAO-Agnostic Data Models
ModeSetting, Links, Skills, and GeneralProfile
# User is the controller of this model
type ModeSetting @createModel(
accountRelation: SINGLE
description: "A mode settings primitive that allows users to toggle between light, dark, and system settings"
) {
author: DID! @documentAccount
mode: Mode!
}
enum Mode {
LIGHT
DARK
SYSTEM
}
___________________________________
# User is the controller of this model
type Links @createModel(
accountRelation: SINGLE
description: "A universal links primitive designed to span various use-cases"
) {
author: DID! @documentAccount
twitter: String @string(maxLength:200)
github: String @string(maxLength:200)
telegram: String @string(maxLength:200)
discord: String @string(maxLength:200)
medium: String @string(maxLength:200)
website: String @string(maxLength:200)
other: [PlatformUser] @list(maxLength: 100)
}
type PlatformUser {
platformName: String! @string(maxLength:200)
userName: String! @string(maxLength:200)
}
___________________________________
# User is the controller of this model
type Skills @createModel(
accountRelation: SINGLE
description: "Standardized skills model for DAO contributors"
){
author: DID! @documentAccount
peopleAndGovernance: Boolean
developmentEngineering: Boolean
growthAndMarketing: Boolean
daoTeams: Boolean
communityManagement: Boolean
discord: Boolean
socialMedia: Boolean
budgetManagement: Boolean
compensation: Boolean
grants: Boolean
web3: Boolean
frontEnd: Boolean
backEnd: Boolean
fullStack: Boolean
UX: Boolean
UI: Boolean
productDesign: Boolean
devOps: Boolean
projectManagement: Boolean
security: Boolean
memes: Boolean
art: Boolean
NFTs: Boolean
graphics: Boolean
branding: Boolean
threeD: Boolean
video: Boolean
communications: Boolean
translation: Boolean
docs: Boolean
writing: Boolean
podcasting: Boolean
strategy: Boolean
treaturyManagement: Boolean
contractAudits: Boolean
multisigs: Boolean
dataAnalysis: Boolean
risk: Boolean
tokenomics: Boolean
contributorExperience: Boolean
other: String @string(maxLength:200)
}
___________________________________
# User is the controller of this model
type GeneralProfile @createModel(accountRelation: SINGLE, description: "A basic general profile") {
author: DID! @documentAccount
firstName: String @string(maxLength:200)
lastName: String @string(maxLength:200)
personalBio: String @string(maxLength:10000)
}
The first four models in our initial library are examples of identity and preference that live a layer beneath DAO-specific identity data buckets. A few notes:
- The array of PlatformUser values in the
otherfield within the “Links” model is meant as a way of future-proofing the data model by allowing users to add additional platforms and usernames. - The SYSTEM setting within the Mode enum (used in the
modefield within the “ModeSetting” model) is meant as a way for the user to designate the default app setting. - Applications that subscribe to these models would query to see if a data instance exists for a given user. If yes, that application could pull that data into the application experience.
Example:
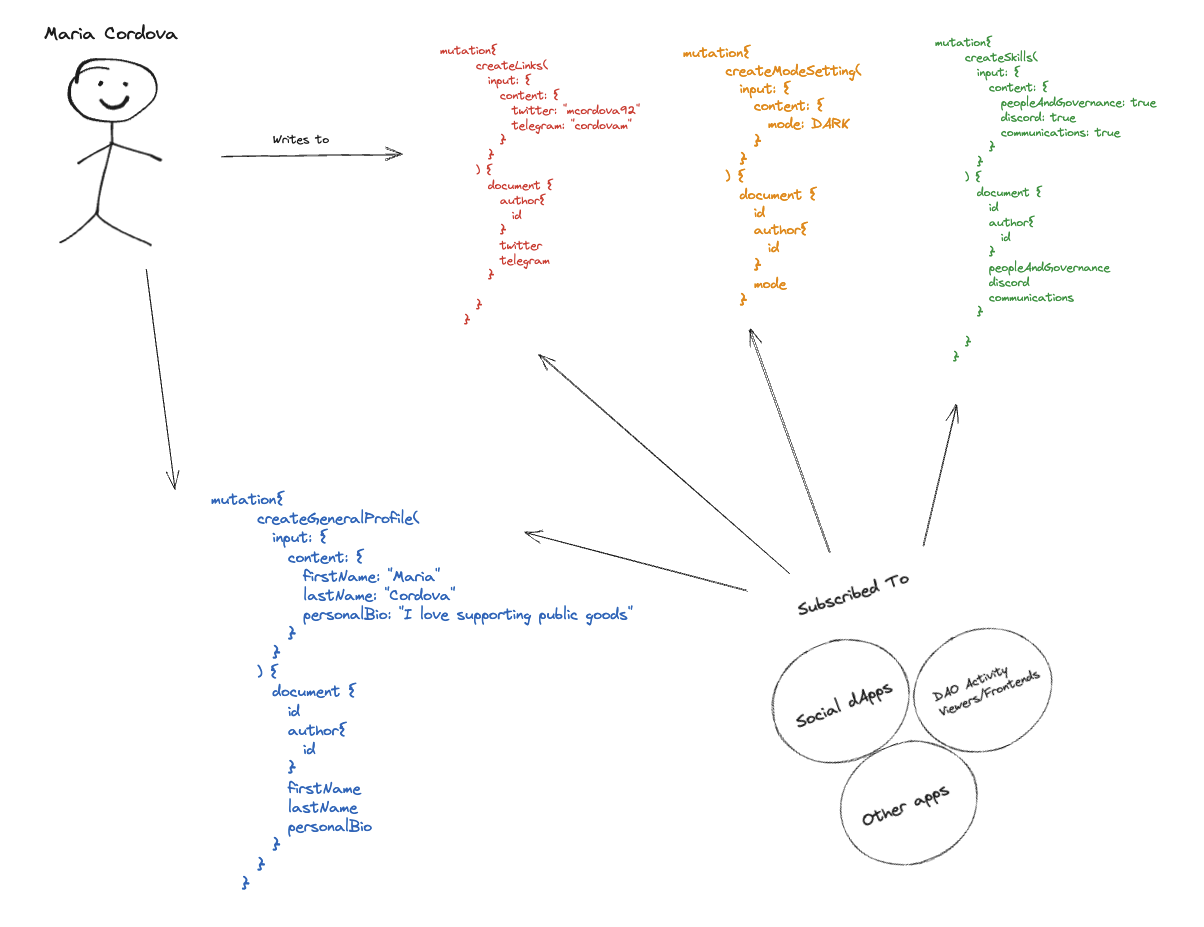
Group-Defined, DAO-Specific Data Models
DAOProfile, Member, and Contributor
# Individual DAO is the controller of this model
type DAOProfile @createModel(
accountRelation: LIST
description: "A simple DAO identifier model"
) {
author: DID! @documentAccount
daoContractAddress: String! @string(minLength:42, maxLength:42)
version: CommitID! @documentVersion
name: String! @string(minLength: 3, maxLength: 150)
description: String @string(maxLength:100000)
members: [Member] @relationFrom(model: "Member", property: "DaoProfile")
contributors: [Contributor] @relationFrom(model: "Contributor", property: "DaoProfile")
}
___________________________________
# Individual DAO is the controller of this model
type Member @createModel(
accountRelation: LIST
description: "A simple DAO-authored member attestation model"
) {
author: DID! @documentAccount
version: CommitID! @documentVersion
memberID: DID! @accountReference
active: Boolean!
DaoProfile: StreamID! @documentReference(model: "DAOProfile")
daoProfile: DAOProfile! @relationDocument(property: "DaoProfile")
role: String @string(maxLength: 150)
}
___________________________________
# Individual DAO is the controller of this model
type Contributor @createModel(
accountRelation: LIST
description: "A simple DAO-authored contributor attestation model"
) {
author: DID! @documentAccount
version: CommitID! @documentVersion
memberID: DID! @accountReference
active: Boolean!
DaoProfile: StreamID! @documentReference(model: "DAOProfile")
daoProfile: DAOProfile! @relationDocument(property: "DaoProfile")
role: String @string(maxLength: 150)
team: String @string(maxLength: 150)
}
The DAOProfile, Member, and Contributor models fall into the group-controlled data category we outlined above and are therefore designed to be authored on behalf of the DAO as a whole. A few notes:
- You’ll notice that the fields for DAOProfile are fairly sparse, which is by design. Please take note of the fields we marked as required (
daoContractAddressandname). - The
memberIDfield serves as both the Ceramic and on-chain identifier given the convention:did:pkh:eip155:1:<on-chain-address>. - The field named
activeis meant to indicate whether the individual is or isn’t currently a member or contributor.
Self-Defined, DAO-Specific Data Models
DelegateOfProfile, ContributorProfile, and MemberProfile
# Delegate is the controller of this model
type DelegateOfProfile @createModel(
accountRelation: LIST
description: "DAO-specific delegate profile"
) {
author: DID! @documentAccount
version: CommitID! @documentVersion
DaoProfile: StreamID! @documentReference(model: "DAOProfile")
daoProfile: DAOProfile! @relationDocument(property: "DaoProfile")
intentStatement: String! @string(minLength: 25, maxLength: 100000)
daoRelevantQuals: String @string(minLength: 25, maxLength: 100000)
}
___________________________________
# Contributor is the controller of this model
type ContributorProfile @createModel(
accountRelation: LIST
description: "DAO-specific individual-authored contributor profile"
) {
author: DID! @documentAccount
version: CommitID! @documentVersion
DaoProfile: StreamID! @documentReference(model: "DAOProfile")
daoProfile: DAOProfile! @relationDocument(property: "DaoProfile")
contributorBio: String! @string(minLength: 25, maxLength: 100000)
optionalAddition: String @string(minLength: 25, maxLength: 100000)
}
___________________________________
# Member is the controller of this model
type MemberProfile @createModel(
accountRelation: LIST
description: "DAO-specific member profile"
) {
author: DID! @documentAccount
version: CommitID! @documentVersion
DaoProfile: StreamID! @documentReference(model: "DAOProfile")
daoProfile: DAOProfile! @relationDocument(property: "DaoProfile")
memberBio: String! @string(minLength: 25, maxLength: 100000)
optionalAddition: String @string(minLength: 25, maxLength: 100000)
}
The DelegateOfProfile is controlled by the delegate, and one delegate can have multiple instances of this document to represent each of their relational identities within specific DAO contexts (aligning with the second data category we defined). One assumption we want to validate is that we believe the only critical self-defining field in this context should be a delegate’s intentStatement as it relates to a specific DAO, with daoRelevantQuals as an optional field where the controller might provide additional context.
ContributorProfile and MemberProfile are similar to the DelegateOfProfile - controlled by the individual contributor who can have multiple instances that uniquely relate to a DAO.
Third-Party Trust and Reputation Signals
DelegateCircleDistribution
# Coordinape is the controller of this model
type DelegateCircleDistribution @createModel(
accountRelation: LIST
description: "A time-series data model to track, index, and analyze inferred delegate contributor value within their circles"
) {
delegateID: DID! @accountReference
version: CommitID! @documentVersion
circleIdentifier: String! @string(minLength: 3, maxLength: 100)
DaoProfile: StreamID! @documentReference(model: "DAOProfile")
daoProfile: DAOProfile! @relationDocument(property: "DaoProfile")
epochEndDate: DateTime!
getTokensReceived: Int! @int(min: 0)
totalTokensAvailable: Int! @int(min: 0)
}
Aligning with the fourth data category we outlined is DelegateDistribution. As we mentioned above, the eventual plan for building out rich, multifaceted delegate data is for many models to be created corresponding to each data category. When it comes to the third-party trust signal category, our thinking is that each model would represent a certain trust attribution framework that DAOs may or may not use.
We will include a brief description related to Coordinape’s framework below:
Coordinape provides a framework and platform for DAOs to determine how to allocate a budget to compensate active delegates within defined time periods called Epochs, and are an ideal example of this concept. We talked with the Coordinape team about how DAOs that use them as a budget coordination tool might represent third-party reputation data. (Note: This is one of a wide variety of concepts that could be used to extend this composite. We welcome feedback with models for your own projects!)
To briefly summarize, DAOs that use this framework allocate a certain number of GIVE tokens (representing a portion of the budget set for member compensation) to active participants (referred to as a Circle). It is then the responsibility of each member of the Circle to distribute to other members of the Circle (based on the perceived value they’ve provided over the course of that Epoch from the allocator’s perspective). For more information read the Coordinape docs.
Given that the GIVE tokens live natively on Coordinape’s server, it would make sense that Coordinape would be the controller of each model instance, authoring new model instances at the end of each Epoch period. As such, a new instance of this model for any given delegate of a specific DAO would be created every Epoch. This allows developers to aggregate and average out data for a delegate over a given period of time, or just the most recent instance. If a delegate is involved across multiple DAOs that use Coordinape in their budgeting logic, developers would also be able to aggregate meta-level delegate insights related to involvement.
Current System Limitations
Before we jump in, it’s important to outline two constraints and their potential implications on how teams would integrate the models into their stack.
Group-Controlled Data Models: The Ceramic Network is designed to support data streams that are individually owned. However, both the group-defined identity and 3rd-party reputation data buckets will require group control of a single DID, which comes with a set of potential risks and vulnerabilities (the possibility of late publishing attacks, for example), and a variety of supplementary technologies and platforms to help facilitate group-authored mutations. For the purpose of this RFC, we are hoping that this implementation ambiguity will spark meaningful conversation around the different ways to securely achieve group authorship, along with a clear understanding of their trade-offs and risk vectors.
Querying/Filtering by Field: Developers cannot currently filter, order, or query by individual field within a given model instance (a feature that comes standard when working with traditional Web2 databases). Note that there is an RFC and active work underway to add this feature within the next several months.
Getting Started
In an attempt to make it as easy as possible to get up and running with this composite library, we decided to go with a cloud deployment methodology. Here are the steps involved:
- Begin following the steps in the Running in the Cloud guide on ComposeDB
- Once you arrive at the section that starts with “Clone the simpledeploy repository and enter the created directory” use the following code instead:
git clone https://github.com/ceramicstudio/delegate-simpledeploy
cd delegate-simpledeploy
- Continue following the guide until you arrive at the sentence starting with "You can now follow the existing guides” - at this point, use the following steps instead:
- Run
npm installwithin the root directory to download the required dependencies - Run
npm run devafter your dependencies have been installed (make sure your terminal is running the correct version of node)
- Run
- You can now perform your GraphQL queries using the following endpoint:
http://localhost:5005/graphql
You can also see how we’ve constructed a sample mutation query for you within the client folder, and how this can be tied so a simple frontend interface. If you’d like to interact with the frontend portion, use the following steps:
- In a new terminal, run
cd clientto enter the client folder - Run
npm installwithin the client directory to download the required dependencies - Run
npm run devafter your dependencies have been installed to experiment with a pre-built mutation query using your new endpoint - Navigate to http://localhost:3000/ to sign in with your Ethereum wallet and perform mutations on your ModeSetting data model. You may have to wait until your new node has finished syncing before accessing data from other users
Please note that this initial composite library uses the Ceramic testnet.
Feedback Guidelines
Any constructive feedback is more than welcome! If possible, pointing us to supporting evidence or documentation that backs up your reasoning for altering the data models would be very helpful.
If providing feedback related to the packaging, deployment, or node access architecture assumptions, we’d love any details you’re willing to provide around the specific needs of your technical stack or configuration to make these deployment packages as frictionless as possible in the future.
We are asking our community for feedback on the following:
- What might we be missing within the data models/composite? What should we consider integrating to optimize for this use case while keeping the models modular and composable to accelerate usage?
- Do the constraints make sense for the fields we’ve defined in our data models?
- Does the packaging make sense for your stack? Does the format make it as easy for you as possible to integrate into your ecosystem? How can we improve?
- Are we making reasonable assumptions related to the burden of data authorship?
Feel free to share your thoughts on relevant models specific to your projects. We’re excited to continue our efforts to help teams build on and work with composable data and would love to engage with other teams with relevant use cases.
Finally, we are asking that our community respond directly (via the forum in which this RFC is posted) as a comment. We are hoping that this will facilitate meaningful, shared learning across community members and engineering teams.